In Oracle, right or wrong, I was always taught to try to avoid “row movement” between partitions due to the general thought that the extra workload of a “delete” + “insert” (rewrite of the row) should be avoided due to the extra I/O, index fragmentation and the associated risks of a migrating ROWID in the cases where the app developers might have used it in their code (now that’s a whole other problem). Oracle didn’t even let you do it by default.
Table by table, you had to explicitly set:
alter table [table name] enable row movement;
Now, you also had to set this to do table reorganizations such as “alter table…. shrink space / shrink space compact” so it wasn’t something unheard of. However, when a customer recently explained to me that they were going to partition a PostgreSQL table and update the partition key column from null to the date when the row got processed, my mind immediately went to the space of that’s probably bad……. RIGHT??
Well, once I thought about it, maybe it’s not all that bad due to the way MVCC and the subsequent VACUUM operations occur in PostgreSQL. The only thing I could think of that might be a factor is that you would lose any potential benefit of HOT (Heap-Only-Tuple) updates since the row will no longer be part of the original partition, seeing that partitions in PostgreSQL are just another table. The benefit though is that I could limit my vacuum operations to one single partition and SMALLER table. A plus for this customer.
**** Note: An implementation like this does not necessarily follow best practices with regards to partitioning. That being said, I was attempting to validate the idea with regards to how PostgreSQL MVCC behaves.
That being said, I wanted to at least be able to prove / disprove my thoughts with a demonstration, so off to PostgreSQL we go. First let’s create a simple partitioned table and use pg_partman to help:
CREATE TABLE partman_test.partman_partitioned (
id integer not null,
val varchar(20) not null,
created_tmstp timestamp not null,
event_tmstp timestamp null)
PARTITION BY RANGE (event_tmstp);
CREATE INDEX partman_partitioned_ix1 ON partman_test.partman_partitioned (id);
SELECT partman.create_parent( p_parent_table => 'partman_test.partman_partitioned',
p_control => 'event_tmstp',
p_type => 'native',
p_interval=> 'daily',
p_premake => 3);
Now, lets insert some random data using a date randomizer function to spread the data across new partitions:
CREATE OR REPLACE FUNCTION partman_test.random_date(out random_date_entry timestamp) AS $$
select current_timestamp(3) + random() * interval '2 days'
$$ LANGUAGE SQL;
INSERT INTO partman_test.partman_partitioned VALUES (
generate_series(0,10000),
substr(md5(random()::text), 0,10),
partman_test.random_date(),
NULL);
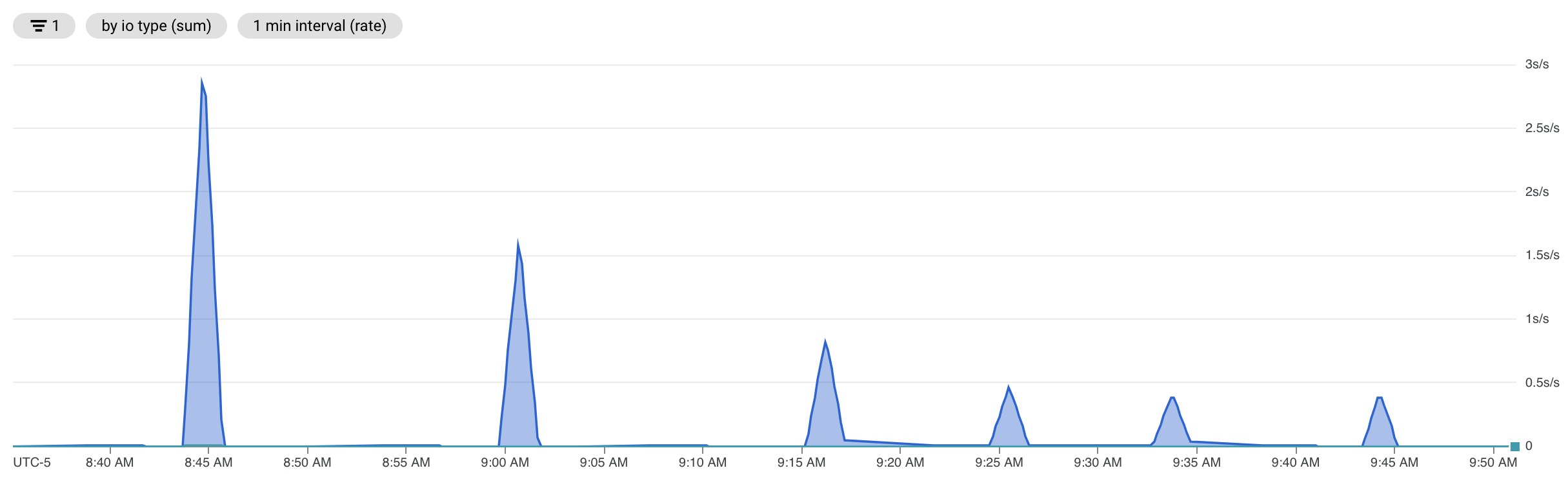
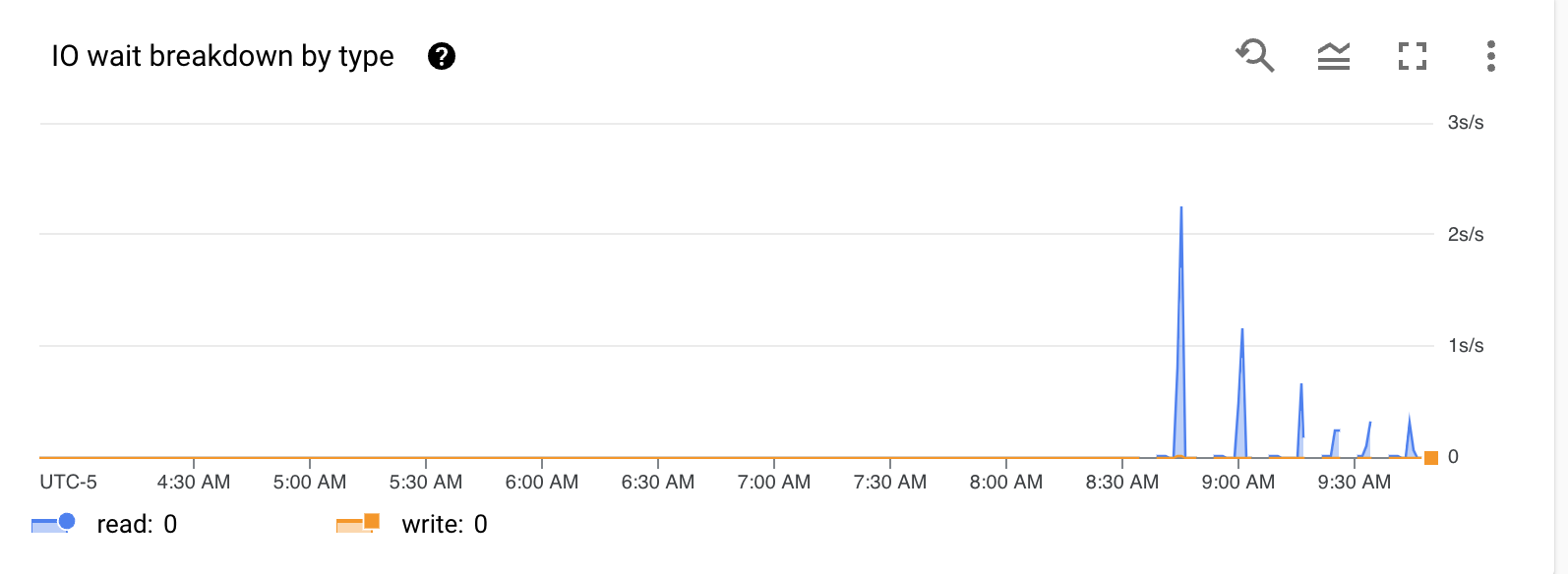
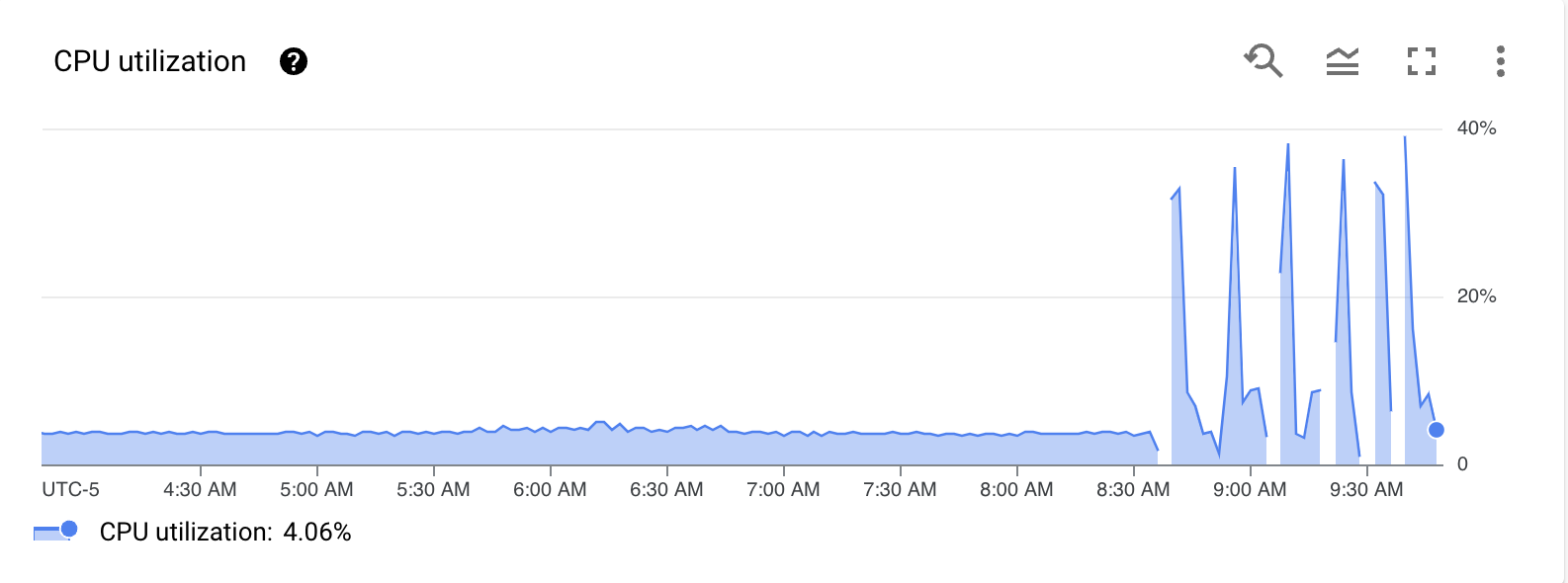
And then for demonstration purposes, I will set autovacuum to “off” for all the partitions” and run 100 updates to move the data into random partitions using the following statement:
ALTER TABLE partman_test.partman_partitioned_default SET (autovacuum_enabled = false);
ALTER TABLE partman_test.partman_partitioned_p2023_09_05 SET (autovacuum_enabled = false);
ALTER TABLE partman_test.partman_partitioned_p2023_09_06 SET (autovacuum_enabled = false);
ALTER TABLE partman_test.partman_partitioned_p2023_09_07 SET (autovacuum_enabled = false);
do $$
declare
v_id integer;
begin
for cnt in 1..100 loop
select id
FROM partman_test.partman_partitioned
WHERE event_tmstp is null
LIMIT 1 FOR UPDATE SKIP LOCKED
INTO v_id;
UPDATE partman_test.partman_partitioned
SET event_tmstp = partman_test.random_date()
WHERE id = v_id and event_tmstp is null;
commit;
end loop;
end; $$;
Once the updates finish, let’s look at the vacuum stats:
relname |autovac_enabled|live_tup|dead_dup|hot_upd|mod_since_stats|ins_since_vac|
--------------------------------------------+---------------+--------+--------+-------+---------------+-------------+
partman_test.partman_partitioned |true | 0| 0| 0| 0| 0|
partman_test.partman_partitioned_default |false | 0| 100| 0| 100| 0|
partman_test.partman_partitioned_p2023_09_05|false | 10| 0| 0| 10| 10|
partman_test.partman_partitioned_p2023_09_06|false | 52| 0| 0| 52| 52|
partman_test.partman_partitioned_p2023_09_07|false | 38| 0| 0| 38| 38|
Extension “pg_stattuple” confirms that dead tuples only exist in the “default” partition. The reason as to why the numbers don’t match pg_stat_all_tables is a discussion for another day:
table_len|tuple_count|tuple_len|tuple_percent|dead_tuple_count|dead_tuple_len|dead_tuple_percent|free_space|free_percent|
---------+-----------+---------+-------------+----------------+--------------+------------------+----------+------------+
524288| 9901| 475248| 90.65| 82| 3936| 0.75| 3308| 0.63|
8192| 10| 560| 6.84| 0| 0| 0.0| 7564| 92.33|
8192| 52| 2912| 35.55| 0| 0| 0.0| 5044| 61.57|
8192| 38| 2128| 25.98| 0| 0| 0.0| 5884| 71.83|
So, we definitely proved that we didn’t get the benefit of HOT updates, but due to the MVCC model of PostgreSQL, the update becomes just like any other non-HOT update. This is due to the fact that the updated row is behaving as if it had an index on the row (primary cause of a non-HOT update and sometimes common) and the rest of the MVCC model is just behaving as it would anyway. I did want to validate with one more tool, but unfortunately the extension, “pg_walinspect” was not installed on this CloudSQL for Postgres instance so I was unable to use it.
What about locks? We do get additional locks to manage because we are effecting two partitions instead of one (but they are all fastpath locks):
(postgres@10.3.0.31:5432) [tpcc] > select locktype, database, relation::regclass, page, tuple, pid, mode,granted,fastpath, waitstart from pg_locks;
locktype | database | relation | page | tuple | pid | mode | granted | fastpath | waitstart
---------------+----------+------------------------------------+------+-------+--------+------------------+---------+----------+-----------
relation | 69323 | partman_partitioned_p2023_09_05 | NULL | NULL | 129825 | RowExclusiveLock | t | t | NULL
relation | 69323 | partman_partitioned_default_id_idx | NULL | NULL | 129825 | RowExclusiveLock | t | t | NULL
relation | 69323 | partman_partitioned_default | NULL | NULL | 129825 | RowExclusiveLock | t | t | NULL
relation | 69323 | partman_partitioned | NULL | NULL | 129825 | RowExclusiveLock | t | t | NULL
If we were to have no row movement between partitions there is a slightly lesser amount of locks to manage:
(postgres@10.3.0.31:5432) [tpcc] > select locktype, database, relation::regclass, page, tuple, pid, mode,granted,fastpath, waitstart from pg_locks;
locktype | database | relation | page | tuple | pid | mode | granted | fastpath | waitstart
---------------+----------+----------------------------------------+------+-------+--------+------------------+---------+----------+-----------
relation | 69323 | partman_partitioned_p2023_09_05_id_idx | NULL | NULL | 129825 | RowExclusiveLock | t | t | NULL
relation | 69323 | partman_partitioned_p2023_09_05 | NULL | NULL | 129825 | RowExclusiveLock | t | t | NULL
relation | 69323 | partman_partitioned | NULL | NULL | 129825 | RowExclusiveLock | t | t | NULL
Also, be aware that you may need to pay special attention to the vacuum operations and settings of the default partition as this type of operation may cause some significant bloat over time. However, one positive is that the bloat will be contained to one and only one partition.
One last caveat that comes to mind. Be sure that either you specify the partition key or explicitly update the “default” partition in your query because otherwise you would get a multiple partition scan which could cause other performance and locking issues.
Enjoy!